Orienter et argumenter ses choix techniques Java avec le microbenchmarking
Orienter/argumenter ses choix techniques Java avec le microbenchmarking
Pour s’adapter au changement dans le monde du logiciel, on souhaite réduire les boucles de feedback.
On hésite parfois entre plusieurs implémentations, en se demandant “Bon, laquelle est la plus performante ?”.
On choisit alors avec un peu de connaissances théoriques et un peu d’intuition.
Mais finalement on a un feedback qu’une fois en production.
Et encore, les performances de notre implémentation sont noyées dans la grande soupe qu’est l’appli.
Le vrai feedback arrive donc bien plus tard, lorsqu’on commence à se dire “elle est un peu lente l’appli, non ?”.
1ère solution pour avoir un feedback atomique et anticipé : être en mesure de construire à la demande un environnement iso-prod, avec volumétrie de prod anonymisée.
2ᵉ solution : Faire des microbenchmarks de nos implémentations et décider tout de suite laquelle garder, avec de solides arguments reproductibles.
C’est ce que nous allons voir dans cet article, avec l’outil JMH.
JMH is a Java harness for building, running, and analysing nano/micro/milli/macro benchmarks written in Java and other languages targeting the JVM.
To stream or not to stream
Prenons comme exemple une question que bon nombre de développeurs Java se sont déjà posé :
Faire un stream pour juste récupérer les libellés de mes 2 statuts, ce n’est pas too-much ?
public record Statut(String label, String code) {
}
public class App {
private final ExtractLabels extractLabels;
public App(ExtractLabels extractLabels) {
this.extractLabels = extractLabels;
}
public static void main(String[] args) {
var app = new App(new ExtractLabelsWithForLoop());
app.run();
}
public List<String> run() {
var statuts = List.of(new Statut("sent", "s"), new Statut("received", "r"));
return extractLabels.extract(statuts);
}
}
public interface ExtractLabels {
List<String> extract(List<Statut> statuts);
}
Première implémentation possible de ExtractLabels :
public class ExtractLabelsWithForLoop implements ExtractLabels {
@Override
public List<String> extract(List<Statut> statuts) {
List<String> list = new ArrayList<>();
for (Statut statut : statuts) {
String label = statut.label();
list.add(label);
}
return list;
}
}
Deuxième implémentation possible de ExtractLabels :
public class ExtractLabelsWithStream implements ExtractLabels {
@Override
public List<String> extract(List<Statut> statuts) {
return statuts.stream().map(Statut::label).toList();
}
}
Dommage, pas de spread-operator en Java …
Dans le vif du sujet : JMH
Tentons de répondre objectivement à la question qui nous anime.
Pour cela commençons par mettre en place les éléments de JMH et contentons-nous d’un microbenchmark de var sum = 458 + 692.
Requirements
- Un projet Maven ou Gradle.
- Un jdk 8+.
Attention à bien utiliser un JDK avec une JVM HotSpot1
Les résultats produits avec une autre JVM peuvent ne pas être fiables :
Extrait d’un benchmark avec une JVM OpenJ9[^3] :
# VM version: JDK 1.8.0_242, Eclipse OpenJ9 VM, openj9-0.18.1
# *** WARNING: This VM is not supported by JMH. The produced benchmark data can be completely wrong.
WARNING: Not a HotSpot compiler command compatible VM ("Eclipse OpenJ9 VM-1.8.0_242"), compilerHints are disabled.
Ajout des dépendances
Pour des résultats plus fiables, openjdk recommande de créer les benchmarks dans un projet dédié :
[…] setup a standalone project that depends on the jar files of your application
Maven
On peut facilement ajouter un module en utilisant la fonctionnalité d’archetype de Maven, avec le même groupId que le parent.
On utilise l’archetype JMH afin d’avoir un pom pré-configuré.
cd my-maven-app
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DarchetypeVersion=1.34 \
-DgroupId=fr.tawane.myapp \
-DartifactId=jmh
Puis on y ajoute la dépendance vers le projet à tester :
<dependency>
<groupId>fr.tawane.myapp</groupId>
<artifactId>app</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
J’y ai aussi modifié la version cible de compilation en 17, pour matcher avec mon projet.
Voici les sources : https://github.com/t4w4n3/demo-jmh/tree/main/gradle
Petit détail sur le pom.xml jmh : le plugin Maven shade permet de packager tout le projet et ses dépendances dans un uber-jar.
An uber-jar is an “over-jar”, one level up from a simple JAR, defined as one that contains both your package and all its dependencies in one single JAR file.
C’est ensuite ce jar-là permet d’exécuter les benchmarks JMH.
mvn package
java -jar target/benchmarks.jar
Gradle
Il est également possible d’utiliser JMH dans un projet Gradle.
https://github.com/melix/jmh-gradle-plugin
J’ai essayé avec succès ce plugin avec un Gradle 7.4.1, c’est vraiment plug-n-play.
Voici les sources : https://github.com/t4w4n3/demo-jmh/tree/main/gradle
Hello World
Effectuons un smoke-test de notre conf avec une somme :
public class MyBenchmark {
@Benchmark
public int sumBenchmark() {
return 456 + 28;
}
}
On lance avec Maven :
mvn package
java -jar target/benchmarks.jar
Ou bien avec Gradle :
./gradlew jmh
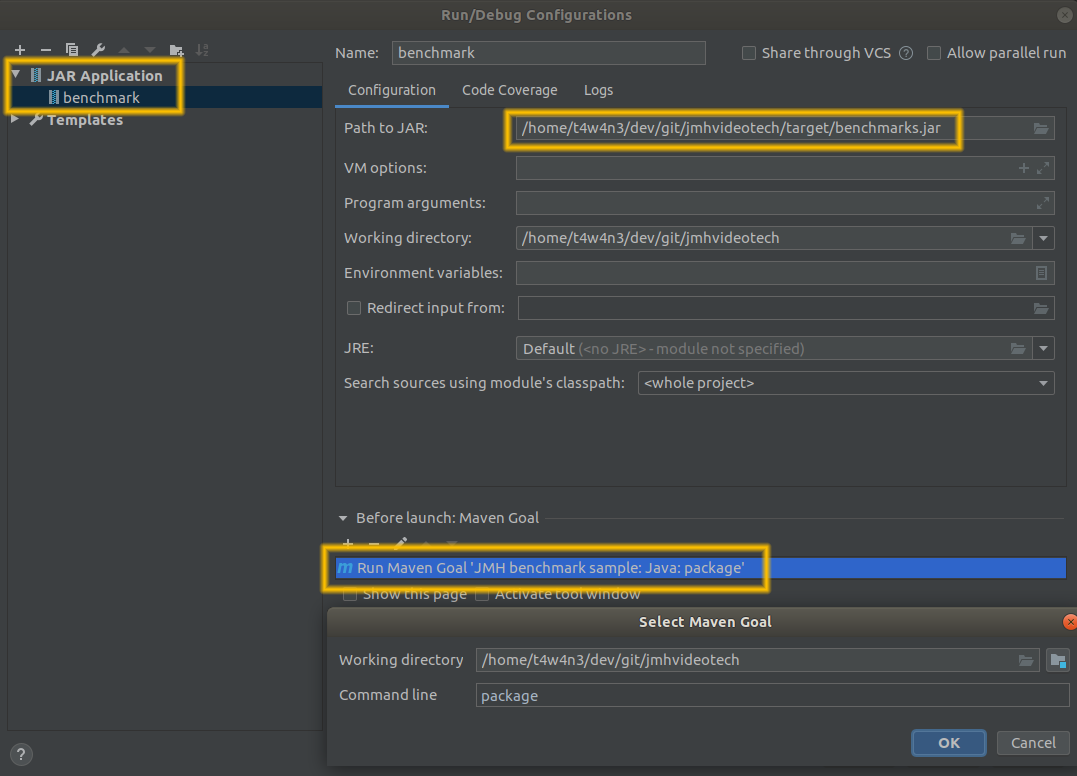
Et avec IntelliJ (et Eclipse), on peut lancer le jar en Run Configuration, avec la step de packaging en Before launch :
Le benchmark démarre, et nous donne quelques informations :
- Les paramètres par défaut
- Le temps estimé de run total
# Warmup: 5 iterations, 10 s each
# Measurement: 5 iterations, 10 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Throughput, ops/time
Examinons ces paramètres de plus prt, afin de les modifier à notre guise :
- Le warmup est une étape de stabilisation du système, où les résultats ne sont pas comptabilisés
- Une itération signifie “looper sur le benchmark autant de fois qu’il est possible dans le temps imparti pour chaque itération” (ici 10 secondes)
- Le Benchmark mode en résumé cela indique l’unité des résultats, ici en opération/seconde
- Les ops (operations) sont le nombre de fois que sont exécutées les fonctions de benchmark annotées.
10 bonnes minutes plus tard, le benchmark est terminé.
Analysons le rapport.
Commençons par le premier fork
# Run progress: 0.00% complete, ETA 00:08:20
# Fork: 1 of 5
# Warmup Iteration 1: 111198226.088 ops/s
# Warmup Iteration 2: 167113291.763 ops/s
# Warmup Iteration 3: 204858584.458 ops/s
# Warmup Iteration 4: 203785995.100 ops/s
# Warmup Iteration 5: 204823311.203 ops/s
Iteration 1: 204785936.513 ops/s
Iteration 2: 204794922.585 ops/s
Iteration 3: 204859967.132 ops/s
Iteration 4: 204682402.359 ops/s
Iteration 5: 204793554.340 ops/s
- “ETA 00:08:20” : Nous avons là le temps estimé total
- Le nombre d’opérations par secondes pour chacune des 5 étapes de warmup, dont on voit que 3 étapes suffisent à stabiliser la jvm.
- Le nombre d’opérations par secondes pour chacune des 5 itérations comptabilisées
Les 4 forks suivants recommencent ce processus, avec une jvm toute neuve.
8 minutes et 25 secondes plus tard, une moyenne générale est calculée et affichée :
Result "gradle.ExtractLabelsBenchmark.sumBenchmark":
185008114.353 ±(99.9%) 22004443.449 ops/s [Average]
(min, avg, max) = (125522161.529, 185008114.353, 204859967.132), stdev = 29375302.453
CI (99.9%): [163003670.903, 207012557.802] (assumes normal distribution)
# Run complete. Total time: 00:08:22
Benchmark Mode Cnt Score Error Units
ExtractLabelsBenchmark.sumBenchmark thrpt 25 185008114.353 ± 22004443.449 ops/s
- Le système parvient à faire environ 185 millions de sommes par seconde
- La marge d’erreur est de 22 millions de sommes par seconde
À chacun d’en tirer les conclusions spécifiques à son contexte.
Le rapport nous indique également une info à lire attentivement au moins 1 fois :
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
C’est pas faux !
En résumé : prenez les résultats avec des pincettes et méfiez-vous du biais de confirmation.
Tweaking params
Bon maintenant que nous savons faire un benchmark par défaut, essayons de modifier les paramètres afin de :
- Voir ce qui nous est possible d’autre
- Avoir un rapport plus rapidement pour
- Pouvoir adapter la profondeur du benchmark à la complexité du code à tester
Commençons par réduire le nombre de fork à 1, car le premier du benchmark de somme donnait déjà une réponse correcte.
Pour ça on utilise l’annotation @Fork(1) :
public class MyBenchmark {
@Fork(value = 1)
@Benchmark
public int sumBenchmark() {
return 456 + 28;
}
}
On peut aussi réduire le nombre d’itérations de warmup à 3.
En changeant cette valeur, l’objectif est d’avoir un score stable entre la dernière itération de warmup et la première de comptabilisée.
Pour ça, on peut aussi jouer sur le temps d’itération.
public class MyBenchmark {
@Fork(value = 1)
@Warmup(iterations = 3)
@Benchmark
public int sumBenchmark() {
return 456 + 28;
}
}
C’est mieux, on a un résultat similaire, mais beaucoup plus rapide à arriver :
# Run progress: 0.00% complete, ETA 00:01:20
# Fork: 1 of 1
# Warmup Iteration 1: 108153911.016 ops/s
# Warmup Iteration 2: 154680012.121 ops/s
# Warmup Iteration 3: 204760242.139 ops/s
Iteration 1: 204718929.821 ops/s
Iteration 2: 204840273.007 ops/s
Iteration 3: 204665606.319 ops/s
Iteration 4: 204727748.183 ops/s
Iteration 5: 204836739.368 ops/s
Enfin, on peut essayer le mode AverageTime, afin d’avoir un résultat en seconde/opération.
Je trouve cette unité plus proche de la question initiale : “C’est plus rapide oui ou non ?”
public class MyBenchmark {
@Benchmark
@Fork(1)
@Warmup(iterations = 3)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public int sumBenchmark() {
return 456 + 28;
}
}
Voila le rapport :
# Run progress: 0.00% complete, ETA 00:01:20
# Fork: 1 of 1
# Warmup Iteration 1: 9.260 ns/op
# Warmup Iteration 2: 6.154 ns/op
# Warmup Iteration 3: 6.430 ns/op
Iteration 1: 5.506 ns/op
Iteration 2: 4.913 ns/op
Iteration 3: 4.889 ns/op
Iteration 4: 4.886 ns/op
Iteration 5: 4.887 ns/op
Benchmark Mode Cnt Score Error Units
ExtractLabelsBenchmark.sumBenchmark avgt 5 5.016 ± 1.055 ns/op
On peut affirmer qu’il faut en moyenne 5 nanosecondes pour faire cette somme sur mon système.
Pour plus de précisions sur les params des annotations, je vous invite à visiter leurs interfaces dans les sources de JMH.
Microbenchmark de l’application de démo
Bien, maintenant qu’on sait installer et configurer JMH, passons au benchmark qui nous intéresse.
@State(Benchmark)
public class MyState {
public App appWithForLoop = new App(new ExtractLabelsWithForLoop());
public App appWithStream = new App(new ExtractLabelsWithStream());
}
public class ExtractLabelsBenchmark {
@Fork(1)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 3)
@Benchmark
public List<String> withForLoop(MyState myState) {
return myState.appWithForLoop.run();
}
@Fork(1)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 3)
@Benchmark
public List<String> withStream(MyState myState) {
return myState.appWithStream.run();
}
}
L’annotation @State
L’étape d’instanciation du JDD ne doit pas être comptabilisée dans le bench.
On le génère donc dans une classe (statique ou pas) annotée de @State.
Son scope se limite aux méthodes de benchmark, ou aux threads (forks).
Cela signifie qu’entre le benchmark de la méthode makeAllYellowDucksQuackWithStreamBenchMark et celui de la méthode filterYellowDucksWithForLoopBenchmark, l’état (State) sera ré-instancié malgré
sa nature statique.
Le rapport
# Benchmark: gradle.ExtractLabelsBenchmark.withForLoop
# Run progress: 0.00% complete, ETA 00:02:40
# Fork: 1 of 1
# Warmup Iteration 1: 50.933 ns/op
# Warmup Iteration 2: 40.718 ns/op
# Warmup Iteration 3: 39.943 ns/op
Iteration 1: 39.201 ns/op
Iteration 2: 39.864 ns/op
Iteration 3: 41.443 ns/op
Iteration 4: 39.961 ns/op
Iteration 5: 39.218 ns/op
# Benchmark: gradle.ExtractLabelsBenchmark.withStream
# Run progress: 50.00% complete, ETA 00:01:20
# Fork: 1 of 1
# Warmup Iteration 1: 133.666 ns/op
# Warmup Iteration 2: 86.560 ns/op
# Warmup Iteration 3: 84.778 ns/op
Iteration 1: 84.732 ns/op
Iteration 2: 85.334 ns/op
Iteration 3: 84.955 ns/op
Iteration 4: 85.676 ns/op
Iteration 5: 84.746 ns/op
Benchmark Mode Cnt Score Error Units
ExtractLabelsBenchmark.withForLoop avgt 5 39.937 ± 3.514 ns/op
ExtractLabelsBenchmark.withStream avgt 5 85.089 ± 1.573 ns/op
Analyse du benchmark
Extraire les libellés des 2 Statut prend environ 2 fois plus de temps sur mon système.
Mais l’ordre de grandeur est très négligeable, on parle ici de 80 nanosecondes.
Je suis bien décidé à conserver la méthode par stream pour une question de lisibilité.
Conclusion
JMH est rapide et facile à mettre en place dans un projet pré-existant, qu’il soit avec Maven ou Gradle.
La configuration par défaut est lente et induit de la redondance, mais est suffisante pour avoir un rapport exploitable dans une majeure partie des cas.
La configuration par annotation est intuitive et flexible.
On peut se servir de JMH pour rationaliser et argumenter ses choix techniques.
Avertissement sur les microbenchmarks
Les microbenchmarks révèlent effectivement que des implémentations sont plus efficaces que d’autres. Cependant, il faut toujours avoir en tête la volumétrie de production, afin de pouvoir répondre à la question : “Est-ce que ça vaut vraiment le coup de refactorer ?” Car il y a d’autres objectifs pour le code, entre autres :
- La lisibilité
- L’évolutivité
- La modularité
Si le gain de temps est de quelques nanosecondes pour très peu d’itérations, on préfèrera conserver une implémentation plus simple, et/ou plus comprehensible. Avant de refactorer, on se re-pose alors les questions :
- “Quelle est ma volumétrie ?”
- “Quelle est la latence max admissible ?”
workloads.
-
Eclipse OpenJ9 is the VM from the Eclipse community. It is an enterprise-grade VM designed for low memory footprint and fast start-up and is used in IBM’s JDK. It is suitable for running all ↩